실제 동작 화면
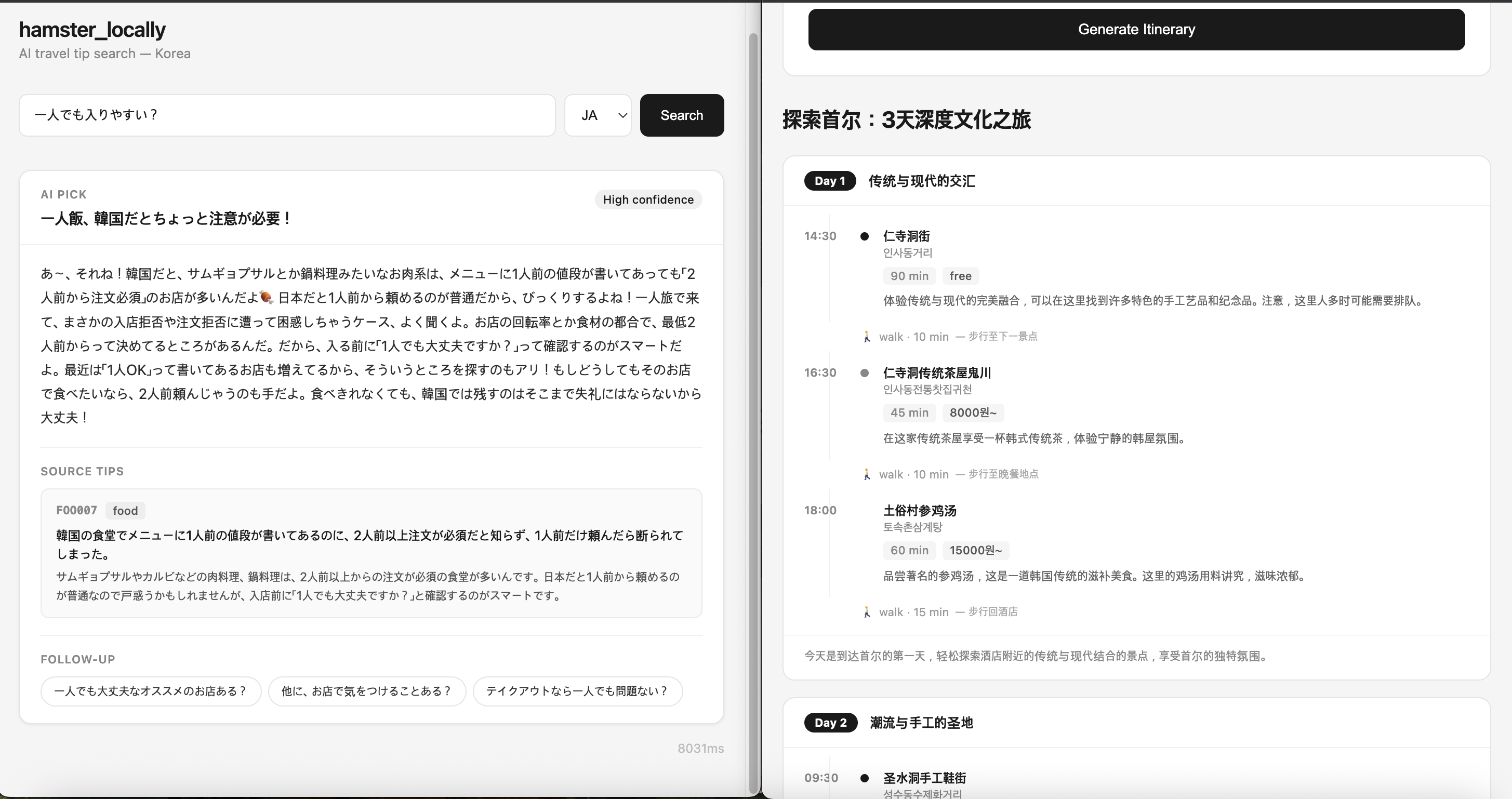
일본어 검색 "一人でも入りやすい?" — 한국 1인 식당 문화를 일본 규범 기준으로 설명 · SOURCE TIPS · FOLLOW-UP 자동 생성 (좌) / 중국어 3일 서울 여행 일정 생성 (우)
일본어 검색 "一人でも入りやすい?" — 한국 1인 식당 문화를 일본 규범 기준으로 설명 · SOURCE TIPS · FOLLOW-UP 자동 생성 (좌) / 중국어 3일 서울 여행 일정 생성 (우)
| 언어 | Reader 프로필 | home_norm 핵심 | key_friction |
|---|---|---|---|
| EN | Western traveler (US/UK/AU) | 직원이 먼저 옴, 팁 필수 15-20%, 첫 줄 서기 신성 | 큰 소리로 직원 부르기, 팁 없음, T-money |
| ZH | 中国大陆游客 | 위챗/알리페이 만능, 흥정 가능, 배달 앱 생활화 | QR페이 제한, 흥정 불가, VPN 없으면 중국 앱 차단 |
| JA | 日本人旅行者 | 벨/버튼으로 조용히 호출, 큰 소리 실례, Suica 카드 | 큰 소리 호출 강한 거부감, T-money 별도 구매, 조용히 기다리다 놓침 |
thinkingBudget: 0 → 빠른 ID 선택만| 패턴 | 적용 위치 | 의도 |
|---|---|---|
| 모델 티어링 | 배치 번역: Pro / 실시간 검색: Flash | 비용 × 품질 트레이드오프 명시적 분리. 1회성 고품질 vs 매 요청 저비용. |
| 2-pass RAG | search() — 1차 ID 선택, 2차 답변 생성 | 전체 팁 컨텍스트 낭비 방지. 관련 팁만 Pro에 노출해 응답 품질 유지. |
| thinking 예산 제어 | 1차: thinkingBudget=0 / 2차: thinking ON | 선택 단계는 속도, 생성 단계는 추론 품질. 각 패스의 역할에 맞게 명시적 설정. |
| 문화 컨텍스트 주입 | 번역 프롬프트 + 답변 생성 모두 | home_norm + key_friction으로 AI가 "차이"를 판단하는 근거 제공. DB 미스 시에도 적용. |
| 구조화 출력 강제 | 번역 · 검색 · 대화 모든 AI 호출 | responseMimeType=application/json + 출력 형식 명시. 파싱 실패 방지. |
| 폴백 체인 | ChatSession — GLM-4 → Gemini Pro | 단일 모델 의존성 제거. GLM-4 장애·할당량 초과 시 무중단 서비스 유지. |
| 히스토리 슬라이딩 윈도우 | ChatSession.history (max 20턴) | 컨텍스트 무한 증가 방지. 오래된 턴 자동 제거로 토큰 비용 통제. |
| 결정론적 큐레이션 | curator.pick_daily() — MD5 날짜 시드 | AI 호출 없이 날짜만으로 재현 가능한 결과. CDN 캐싱 / 서버리스 환경에 유리. |